Previous:
Problems Commands Group 🧩
This group contains commands that are releated to LeetCode problems. In other words, all commands interacts with LeetCode in order to fetch, download and inspect specific problems. Must be noticed that, although LeetCode itself does not provide a public documented API, using simple tool like Web Developer on the Browser, Burpsuite or just searching online, it is possible to see how LeetCode itself is looking for problems and more over. In particular, all commands in this section use the GraphQL LeetCode endpoint:
https://leetcode.com/graphql
GraphQL
Before moving deeply into the details of each different command, although it is not necessary, one should at least understand what’s GraphQL. If you are not interested, just move on to the next section in the page. As they state, GraphQL is a query language for the API and a server-side runtime for executing queries using a type system the user should define. After a GraphQL service (server-side) is running (typically at a URL that ends with /graphql), it can receive GraphQL queries to validate and execute from clients.
The GraphQL specification does not require particular client-server protocols when sending API requests and responses, but HTTP is the most common choice because of its ubiquity, and with LeetCode this is the case. An HTTP server, to be compatible with GraphQL, must be able to handle HTTP POST Requests for query and mutation operations (optionally also GET). A classical GraphQL POST request look like this:
POST /graphql HTTP/1.1
Host: https://leetcode.com
Accept: */*
Content-Type: application/json
<Other Headers ...>
<query>
Since the Content-Type header field is set to application/json, this means that the query would be a JSON-encoded body of the following form:
{
"query": "...",
"operationName": "...",
"variables": { "myVariable": "someValue", ... },
"extensions": { "myExtension": "someValue", ... }
}
The query parameter is required and will contain the source text of a GraphQL document. Instead, the operationName, variables and extensions parameters are optional fields. Note that, if the Content-Type header is missing in the client’s request, then the server will respond with a 4xx status code. Using the GET method, the request will look different.
Once the server has received, validated and exected the GraphQL query, it will send an HTTP Response. The result of the query is returned in the body of the response in JSON format that will look like this:
{
"data": { ... },
"errors": [ ... ],
"extensions": { ... }
}
If no errors were returned, the errors field will not be present in the response body. On the other hand, if errors occurred before execution could start, the errors field will include these errors and the data field won’t be present in the response. The two fields will be present in the response together in cases of partial success, for example setting data to null and errors to corresponding value. In this last case, HTTP Status Code of 2xx is obtained.
This is all about GraphQL, for what’s we are interested in. Now, let’s step to the commands.
1. List command
Syntax: list
The list command extracts a list of problems from LeetCode and save it locally in the application state. At this stage, no local instance is yet created, however fetched problems are present in the application “memory” ready to be downloaded.
This is the corresponding GraphQL query:
#graphql
query problemsetQuestionList($categorySlug: String, $limit: Int, $skip: Int, $filters: QuestionListFilterInput) {
problemsetQuestionList: questionList(
categorySlug: $categorySlug
limit: $limit
skip: $skip
filters: $filters
) {
total: totalNum
questions: data {
acRate
difficulty
freqBar
questionFrontendId
isFavor
paidOnly: isPaidOnly
status
title
titleSlug
topicTags {
name
id
slug
}
hasSolution
hasVideoSolution
}
}
}
As you might see from the above query, it takes as input (variables, as named by GraphQL) four parameters. The $categorySlug parameter filters the returned problem list by the category, e.g., "algorithms". The $limit parameter limits the number of problems that we obtain from the query. The $skip parameter, instead, specify how many number of problems to skip before fetching the result. Finally, the $filters variable represents other filters for example the difficulty, problem tags or company.
An example of HTTP POST Request body could be:
{
"query": "<above query>",
"variables": {
"categorySlug": "algorithm",
"limit": 100,
"skip": 20,
"filters": {"difficulty": "EASY"}
}
}
All filters are configurable by setting some variables belonging to the state of the application. If you are interested, checkout the set command in the corresponding State page.
For now, leaving the state as it is, here is an output example when running the list command:
[DD/MM/YYYY, HH:MM:SS PM/AM] >>> (Type help for commands): list
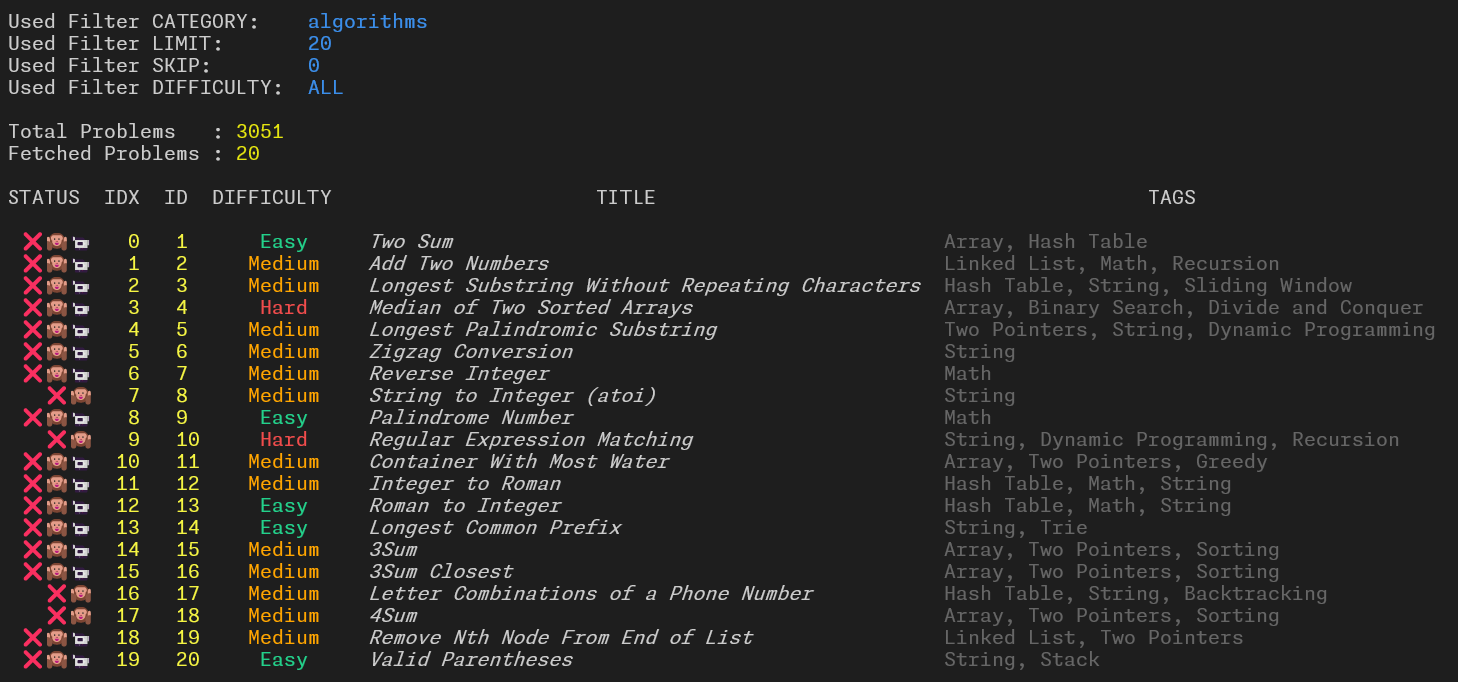
At the top filters are specified, then total number of problems for the given category and total number of fetched problems are displayed and, finally, the problem list is printed in a table formatted way. As you can see there are six main columns: STATUS, IDX, ID, DIFFICULTY, TITLE and TAGS. The content of the last four columns it is enough esplicative I think, thus let’s talk about the first two.
The Status column display some useful informations about the state of the problem. In particular, it identifies if the problem has already been solved by the currently logged in user (if any) using ❌ as “No” and ✅ as “Yes”, if the solution is public (🙉) or premium only (🙈) and, if the video solution is available (📹).
In the current version, i.e.,
v0.1.1, the status column does not show an information, i.e., if the corresponding problem is already beeing downloaded or not locally. In positive cases the emoji 🔗 should appear.
The Idx column display the index of the corresponding problem in the application problem list. That is, this column contains the local indexing for the respective problem, while the Id column represents the remote ID, or more specifically the Frontend ID of the problem (which is actually different from the question ID, although sometimes they match).
Fetched problems are saved into the current state of the application. This means that to see which problem is available to be downloaded, it is sufficient to inspect the state, instead of resubmitting the
listcommand everytime.
2. Fetch command
Syntax: fetch <NAME|ID> VALUE
The fetch command is used to extract a single precise problem from the list available on LeetCode. It takes two required parameters. The first one, identified by either NAME or ID, specify the content of the other one, i.e., the VALUE parameter which is user to filter which problem needs to be fetched.
If NAME is given, then the VALUE parameter must coincides with the title-slug of the problem we want. The title-slug (or titleSlug in some GraphQL queries), identifies the title of the problem formatted as lower-case letters with spaces replaced by the - symbol. For example, the Two Sum problem has as title-slug two-sum or the Letter Combinations of a Phone Number corresponds to letter-combination-of-a-phone-number. Now, some of them might not follow the same rule, hence for any further detail consider using the detail command.
On the other hand, if the ID value is given, then the VALUE parameter must coincides with the ID of the problem.
In this case, two different GraphQL queries are used. The first is:
#graphql
query selectProblem($titleSlug: String!) {
question(titleSlug: $titleSlug) {
questionId
questionFrontendId
title
titleSlug
content
isPaidOnly
difficulty
similarQuestions
exampleTestcaseList
topicTags {
name
slug
}
codeSnippets {
lang
langSlug
code
}
stats
hints
solution {
id
canSeeDetail
paidOnly
hasVideoSolution
paidOnlyVideo
}
status
sampleTestCase
mysqlSchemas
enableRunCode
enableTestMode
enableDebugger
note
}
}
The
selectProblemquery represented previously it is not the actual used query. In successive versions, the current query will be changed with this one. This will not impact the amount of useful gathered informations, it will just reduce the number of data provided by the API.
While the second one is already exposed in the list command section. Differently from the previous explained query, this new one gathers detailed information about a single question, which are way more useful with respect to those provided by the list query. However, some informations from the other query is not present in this one, so we must keep both. We will see this query being used elsewhere, but in this case it is only required in case the NAME option is passed to the command. Given the name we fetch the Question Frontend ID from the response and then use the other query to obtain what the application need.
// selectProblem Query Request body
{
"query": "<selectProblem Query>",
"variables": { "titleSlug": "two-sum" }
}
// problemsetQuestionList Query Request body
{
"query": "<problemsetQuestionList Query>",
"variables": {
"categorySlug": "algorithm",
"limit": 1,
"skip": "<the ID of the two-sum problem - 1>",
"filters": {}
}
}
The normal output does not diverge from the list command output.
However, if the question is already fetched a green message should appear:
[INFO] Question seems already fetched
Any other outputs, different from the previous one, represents errors.
It happens that, when using the
fetchcommands and theIDoption, problems are fetched no matter if they are already present in the application or not. This will be fixed in versions> v0.1.1.
3. Detail command
Syntax: detail VALUE [BYID|BYIDX]
The detail command is used to obtain more useful informations about a given problem rather than with previous commands. It has one required and one optional parameters. The last one identifies the meaning of the first parameter. In particular, if BYID is given than VALUE represents the frontend id of the question. On the other hand, if BYIDX is given, VALUE indentifies the position inside the locally fetched list of problems. This distinction has been made to ensure already fetched problems not being queried multiple times. Since the second option is optional, if empty by default BYIDX is used.
The currently used query is the list one. Here is an example of the output:
[DD/MM/YYYY, HH:MM:SS PM/AM] >>> (Type help for commands): list
[DD/MM/YYYY, HH:MM:SS PM/AM] >>> (Type help for commands): detail 0
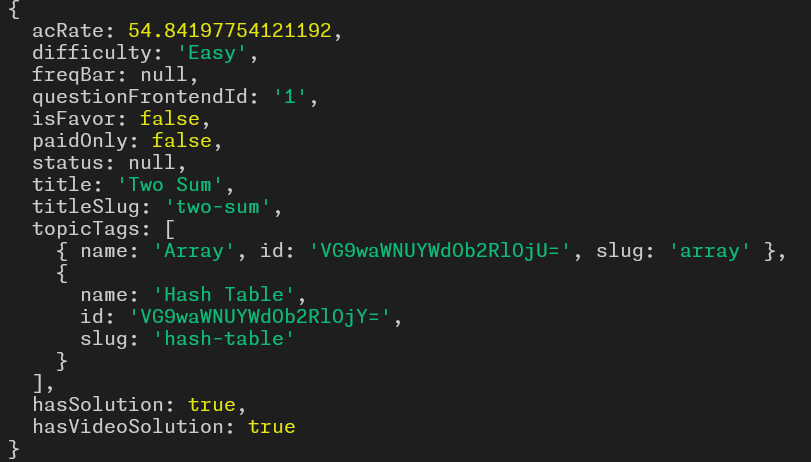
The output of the command is still in an early development stage since it does not provide the entirety of the informations.
Without changing any filter, the previous sequence of commands give the same output of:
[DD/MM/YYYY, HH:MM:SS PM/AM] >>> (Type help for commands): detail 1 BYID
4. Create command
Syntax: create [IDX]
The create command, creates a local instance of a fetched problem identified by the local index IDX, or several local instances, one for each fetched problem, if not index is provided. Where is this index located? Inspecting the current state of the application using the show command, it is possible to visualize all locally fetched problems and take the corresponding local index.
What is a local instance of a problem? In this context, an instance is just a folder, which name follows the syntax <id>-<titleSlug>, that contains four files:
README.mdcontaining the description of the problem in Markdown formatindex.htmlcontaining the description of the problem in HTML formatsolution.py, a Python file containing the solution (the user should written)tests.txt, a Plain Text file containing the test cases provided by LeetCode
Here is an example of the solution.py file content for the two-sum problem:
"""
QUESTION TITLE: Two Sum
QUESTION LINK: https://leetcode.com/problems/two-sum
QUESTION TAGS: Array, Hash Table
QUESTION LEVEL: Easy
"""
from typing import *
# SOLUTION STARTS
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
...
and the tests.txt file:
[2,7,11,15],,9
[3,2,4],,6
[3,3],,6
To fetch all informations in order to create the instance, this command uses the selectProblem GraphQL query previously described.
Here is an example of the output:
[DD/MM/YYYY, HH:MM:SS PM/AM] >>> (Type help for commands): fetch NAME two-sum
[DD/MM/YYYY, HH:MM:SS PM/AM] >>> (Type help for commands): create 0
[INFO] Result written in folder: problems\1-two-sum
Let me explain what’s happened. Assume a clean environment, e.g., a first start. First, the fetch command has fetched the two-sum problem locally into the application state. Since it is the only question available it has index 0. Finally, the create command with index 0 has created a local instance of the problem. Notice that we would have obtained the same result without providing any index (there is just one question right now).
From the output we can see that the instance folder has been successfully created and placed into a problems folder. This directory is customizable by the user and, again, it is a variable inside the state of the application (checkout the usual set command). At the end, each instance will be saved into a path <folder>/<id>-<titleSlug>.
Notice that Python is the only target language currently available.
5. Daily command
Syntax: daily [create]
The daily command can be used to fetch currently available daily question and, using the optional create option, to create a local instance. Note that the daily question is automatically fetched when the application starts, hence there is no need to call the daily command without the create parameter, unless the problem has been remotely updated during the session.
The following GraphQL query is used to fetch daily questions:
#graphql
query questionOfToday {
activeDailyCodingChallengeQuestion {
date
userStatus
link
question {
acRate
difficulty
freqBar
questionFrontendId
isFavor
paidOnly: isPaidOnly
status
title
titleSlug
hasVideoSolution
hasSolution
topicTags {
name
id
slug
}
}
}
}
The current daily question is not shown in the current state, indeed it is save into it.